Idea To Merged In Less Than 30 Minutes: An Experience Contributing To Open Library
Search for a command to run...
No comments yet. Be the first to comment.
Notion isn't exactly known as a speed demon... On Android it can take 30+ seconds to share a URL to the Notion app. It's faster to paste the link in the Notion app directly. I know because I do it 10-
When dad’s phone died I was the first one mom called for help. She always apologizes when calling for help. I’m not sure if she’s just being polite or she really doesn’t know the joy it brings me to b
Last year, I learned QGIS through the GIS and Spatial Analysis for Urban Practitioners course by All Things Urban. This year, with free Udemy access via SFPL, I'm looking to expand my skills. First, I dug up my old final project to revisit and share....
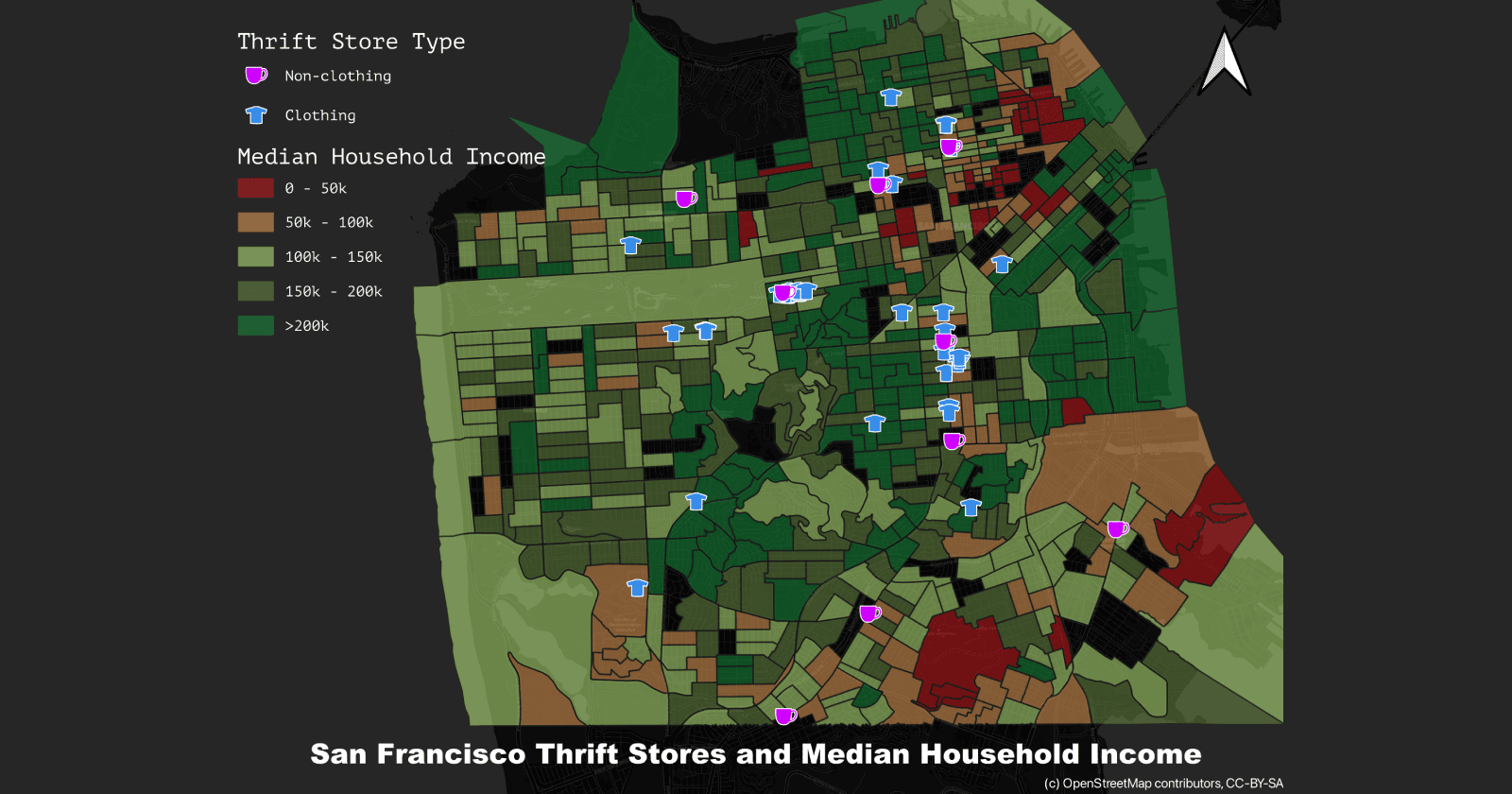
TLDR: I made a tool to do this: Wikidata string to QID tool (source). Bulk adding information to Wikidata by hand is a pain. I have an idea for creating a map of MVNOs (mobile virtual network operators) and their ownership (AT&T owns Cricket, Verizon...
Friends often joke about how bad FixBus is but none of the ~10 rides I've been on were particularly unpleasant. In fact, this most recent bus even had 250 MB of free WiFi. I didn’t bother using it but I found it to be an amusingly small amount for a ...

Today, I had such a wonderful experience contributing code to Open Library that I felt compelled to write a short blog post about it.
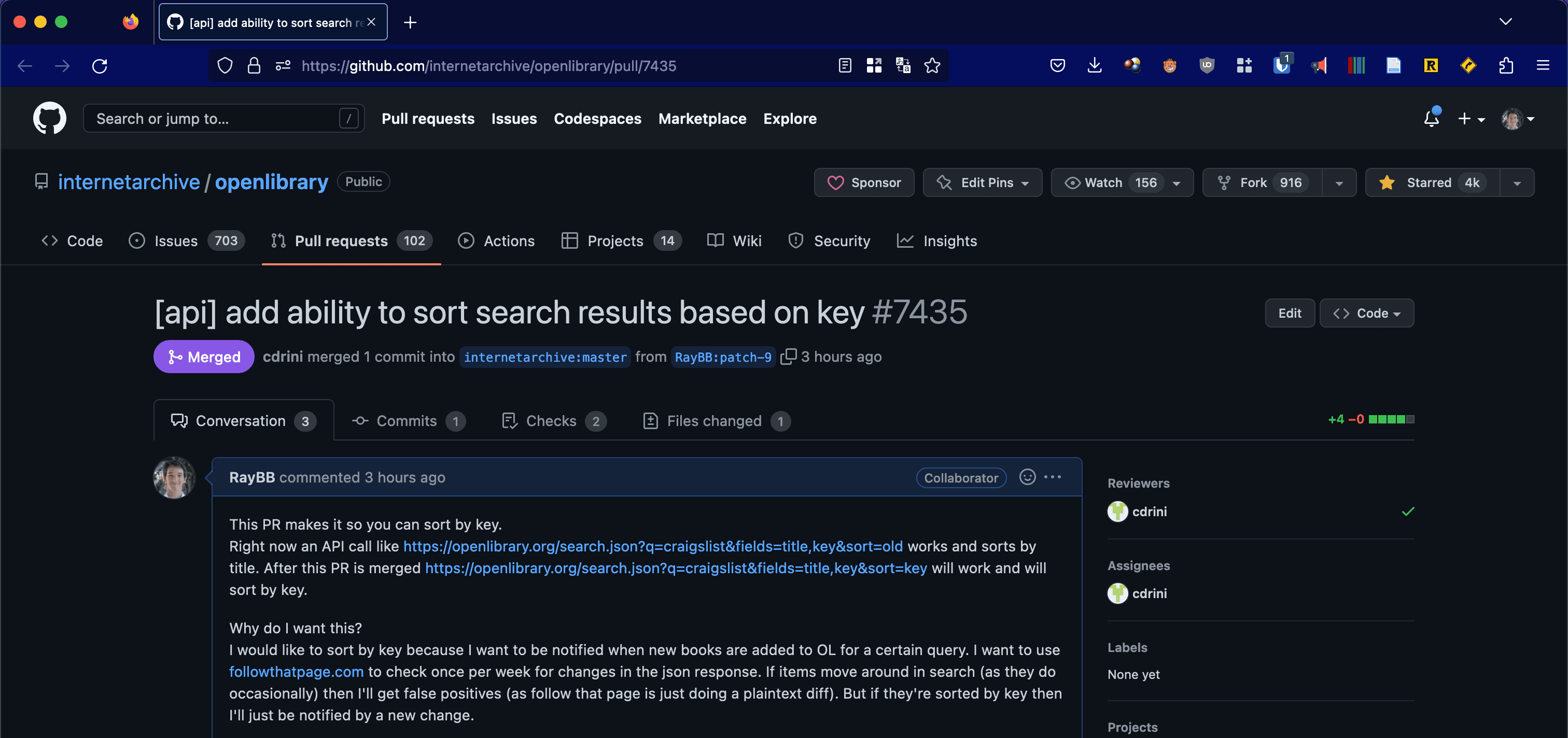
Summary: I found out why the search API wasn’t working as I expected and had my fix merged less than 30 minutes later.
I’ve contributed to Open Library’s codebase before but haven’t been active recently. Though, I also help as a Librarian and occasional mentor. They're always looking for more designers, translators, and general volunteers.
Open Library is an amazing project that's part of the Internet Archive. It enables anyone to legally read books for free and has a full-text search of the millions of available books.
I wanted to use followthatpage.com to get notified when new books are added and the search results for a query change. Follow That Page only does a simple text diff and the original API call I was making https://openlibrary.org/search.json?q=craigslist contained the full JSON of all the books. Unfortunately, when anything about any of the books changed I would recieve a large diff.
I realized I could use the fields query param to only get the title and key (book id) of the works like this: https://openlibrary.org/search.json?q=craigslist&fields=title,key. I also noticed that the books were sorted by relevance. I’m not sure how relevance works but I’ve seen search result order change when I’ve added more information to books. So I decided to try sorting the books by their title following the search API docs. Unfortunately, the docs were a bit confusing and I didn’t know why I couldn’t sort by the key.
I popped into Open Library’s Slack and posed the question:
API call: https://openlibrary.org/search.json?q=craigslist&fields=title,key&sort=key
Drini, an Open Library maintainer, responded in a few minutes letting me know that we can only sort by a few allowed facets and asked why I wanted to sort by key.
I explained my idea to be notified of new works added for a certain search and he kindly pointed me to the file I would need to modify to do what I wanted. He confirmed I could follow the convention random was already used, which enables sorting in ascending or descending order.
Since Open Library's dev wasn't on my computer, I used the GitPod button (which I set up for Open Library a year ago) in the README and had a dev environment ready to go in minutes. I tweaked the file needed to sort by key and tested the API in GitPod. Everything looked good.
I’m not that familiar with GitPod’s workflow for creating pull requests (PRs) so I just went to the file in GitHub and edited it via the web IDE.
I recorded a demo video of my change working in GitPod for the PR. Then I filled out the rest of the details for the PR and posted it on Slack:
“Hey @Drini, not asking you to review now. But just letting you know I did open a PR and hope it can get in the queue to be checked out!”
Six minutes later the code was running on the test environment and promptly merged. After the next weekly deploy it will be in production. The docs are already updated!
Thank you so much to Drini, Mek, Christian and the rest of the team at Open Library (and the Internet Archive) for always providing a kind and supportive community. It is no small feat to foster such collaboration with a lean team.
PS: You should not expect this level of responsiveness from most open source projects. This is a big project with a small team working full time that has made it a high priority to engage with the community. Again, kudos to them for pulling it off.